








")












If you’ve come to be entertained by beautiful pictures of Hangzhou and stories of my adventures to far away places, I regret to inform you that you won’t be getting it here this week. The only pictures you’ll be seeing on this post will be red rectangular boxes overlaid on screenshots from League of Legends, and the only adventures to be had are those of my struggles with OpenCV. With the AI Empowered Design theme project well and truly kicking into gear, I’ve spent the past five days doing literally nothing but eating, sleeping, and coding (seriously, I’ve only left my room for lunch, dinner, and a project meetup). At any rate, the weather (constant rain interspersed by scalding heat) has made it difficult to plan any trips.
But just in case you aren’t remotely interested in any of that stuff, here’s a couple of photos I was able to take from the confines of my room, so that you won’t leave completely unsatisfied.


Fortunately, this also means that significant progress is being made on the project. As mentioned in my previous post, my theme project is on live video abstraction. We’ve decided to narrow our scope down to League of Legends streams on Twitch, and aim to generate real-time video summaries that can assist new viewers in catching up to the action.
Sourcing for the stream
The first step to doing any of this is, of course, obtaining the live video to work on. This proved to be a bit more challenging than I expected. First off, there was the issue of obtaining the actual stream source from the Twitch page. Although the live video is embedded within each Twitch streamer’s page, I’d need the actual raw video source to work with. Fortunately, this was quickly solved with the help of Streamlink.
That turned out to be the easy part – I still needed a way to load and convert the video to a usable format. Although OpenCV possesses the capability to directly capture videos from the source link, it was unable to keep a buffer of frames while the current feed was playing. This meant that using OpenCV to load the live video would result in consistent freezing every few seconds while the next set of frames were being downloaded. After spending a sizable amount of time scouring the interwebs, I eventually managed to work around this by creating a separate thread that used FFmpeg to write the raw video frames to a buffer for OpenCV to work with.
Now that we had the capability to access the live video source, the next step was to find and extract information from the stream that might be able to tell us whether a particular portion of the match was important to the game ‘narrative’. We identified a few potentially extractable quantitative metrics, such as the health of the streamer’s player, the total number of players on the screen, the volume of the stream, as well as various other in-game labels. On my part, I’ve been working primarily on the first two categories for the past week.
Reading player health
The first method I attempted to use in reading the health of the player was to try and detect the width of the health bar. I approached this by first finding a region of the screen in which the entirety of the health bar was guaranteed to appear in, then applying a colour filter tuned to the health bar colour such that I could obtain an outline of the health bar. I then hit a dead end – although it was easy enough to detect the health bar itself, the information I really needed was the location of the start and end limits of the health bar. The start was easy enough to find, since it would always remain constant on the left side. However, since the health of the player could be expected to be varying, and different players had their UI elements at slightly different positions, there was no way to reliably determine where the end of the bar was.
I attempted a few more different methods, such as edge and contour detection, to determine the boundaries of the health bar (with mixed success), before eventually deciding to go for a more direct approach of trying to perform optical character recognition on the numbers at the center of the health bar. Fortunately, I didn’t have to build my own optical character recognition engine from scratch – instead, I made use of Tesseract. The challenge now was to locate and clean up the health numbers sufficiently for the OCR engine to give a satisfactory result. To achieve this, I first applied an inverted version of the colour filter I had previously already used, to subtract the health bar colours from the image instead, before thresholding the image into a binary image with crisp and identifiable characters.

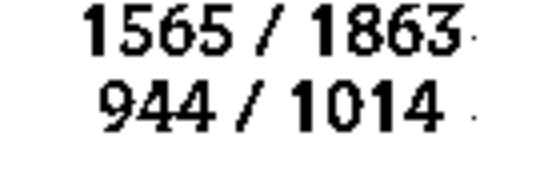
Health bar detection
The next challenge I took on was that of finding the number of players on the screen at any given time. Since each player will have a health bar (different from the one in the previous section) above them at any time, this equates to finding the number of said health bars. There were two obvious approaches to this using OpenCV: the first, cascade classification, and the other, template matching. Since I didn’t want to have to create hundreds or thousands of negative and positive health bar samples, I went with the template matching approach.
Unfortunately, there exist four different colours of health bars, which can, at any point in time, be at varying levels of health. Since template matching is highly specific, this meant that I had to generate a sufficient number of health bar templates of different colours and health levels anyways (still far less work than building a cascade classifier, though). I ended up with a total of 168 templates.
However, the massive number of templates came at a cost. Since each and every template had to be run through the entire image, detecting the number of health bars in even a single image took a very long time. Even at a downscaled 480p resolution, the health bar detection algorithm required five and a half seconds to run through just one frame. The good news, though, was that this setup was capable of detecting the health bars with reasonable accuracy, successfully detecting 86.8% of actual health bars with a false positive rate of 3.4%.

While the detection accuracy wasn’t really as high as I’d hoped for it to be, upon further inspection, it turned out that the failed detections were largely due to the health bar being blocked in some way, as shown below (I even missed some of the ‘undetected’ health bars when going through the images myself).
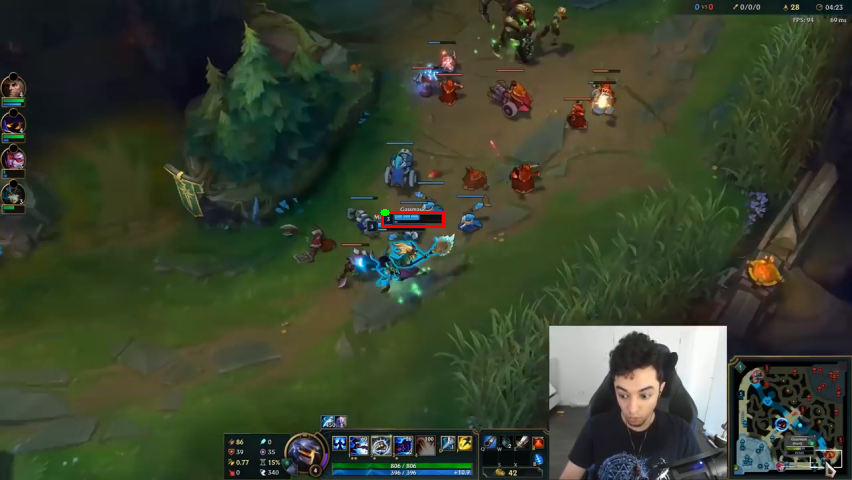

I then continued work on reducing the time needed for detection. I eventually succeeded by modifying the detector to run through two passes. The first pass would scan the entire image in grayscale with a higher tolerance, creating a list of candidate regions. Because the first pass was run in grayscale, only a single ‘colour’ of templates was needed, reducing the number of templates for the first pass to 42. The second pass would then go through each of the candidate regions generated by the first pass with the same settings as the original single pass detector. This meant that the total area to be run through by the full number of templates was significantly reduced, thus cutting the detection time required.

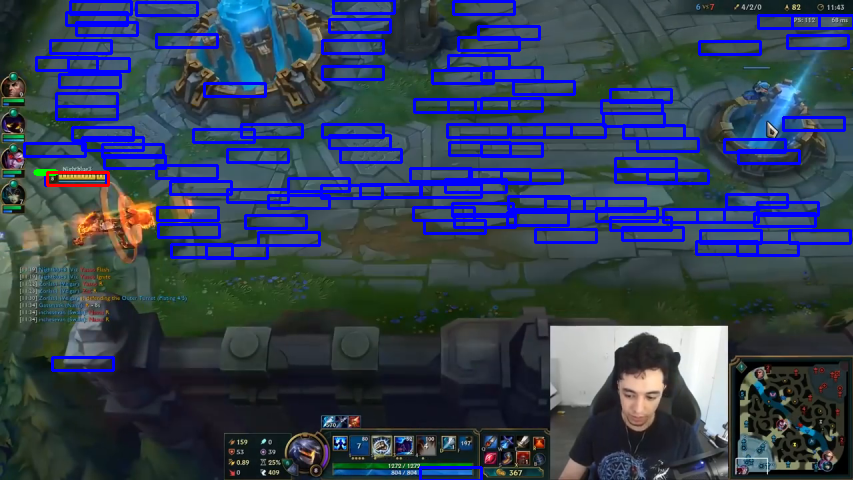
All in all, the fast detector reduced the time required to 0.93 seconds per frame – not nearly fast enough to run a real-time detection parallel to the stream, but still sufficient for a much higher precision in generating our game metrics from the stream. The overall detection rate also dropped to 83.2%, due to the first pass missing out some of the health bars.
Moving forward, I’ll most likely be working on reading some of the other in-game labels and textual information which pop up from time to time (in addition to trying to improve on both the player health and health bar detection algorithms I already have in place). I’ve also yet to fully implement optical character recognition for some of the other relevant information on the screen (gold, kills/deaths/assists, and game time), although those shouldn’t be too much work (it’s more of a matter of identifying the correct region of the screen to read from).
But before all of that, I think it’s seriously time for me to get some time out in the sun…










{kind=link}